2021. 4. 3. 01:18ㆍ민공지능/음성 인식 프로젝트
Mel Spectrogram
- 주파수 특성이 시간에 따라 달라지는 오디오를 분석하기 위한 특징 추출 기법
- Mel-scale(Melody scale)
- pitch에서 발견한 사람의 음을 인지하는 기준(threshold)을 반영한 scale 변환 함수
- Pitch = 음의 높낮이(진동수 Hz의 크고 작음과는 다르다.) : Pitch는 보다 추상적인 개념이다. 사람은 소리의 Hz가 저주파일 때 더 민감하게 인지하고, 고주파로 갈수록 둔감해진다는 점에서 출발한 개념이다. 이를 just-noticeable differences(==threshold)라고 한다.
귀의 구조로 인한 차이
출처: https://hyongdoc.tistory.com/402 [Doony Garage]
- 사람은 200Hz와 1200Hz 소리는 쉽게 구분할 수 있지만, 12000Hz와 13000Hz는 같은 1000Hz 간격임에도 불구하고 구분하기 어렵다.
- 동일한 세기로 100Hz 소리를 들려줄 때와, 10000Hz 소리를 들려줄 때 사람이 느끼는 세기는 다르다.
- (인간이 이해하기 힘든) Spectrogram의 y축을 Mel Scale로 변환한 것 (Non-linear transformation)
- 보통 고주파로 갈 수록 사람이 구분하는 주파수 간격이 넓어지는데 이를 반영해주는 mel scale을 적용
https://youtu.be/xpfHpzjoDEg?t=54

- 프레임의 길이와 슬라이딩 범위를 하이퍼 파라미터로 설정

librosa 공식 홈페이지에 음성 처리의 경우엔 n_fft를 512를 기본값으로 권장한다고 적혀있다.

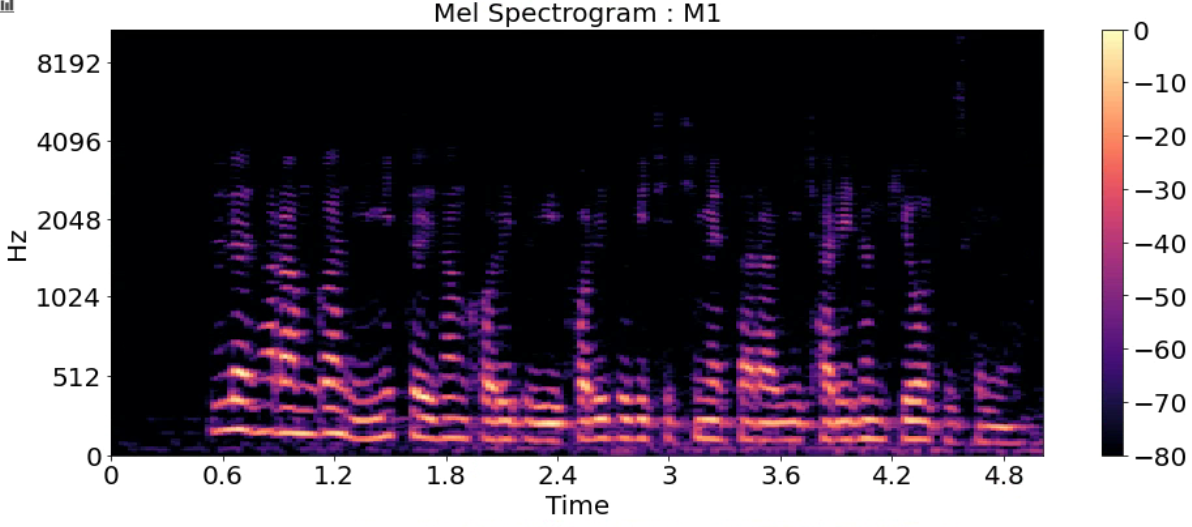
title = ['Mel Spectrogram : F1_high','Mel Spectrogram : F1',
'Mel Spectrogram : F2','Mel Spectrogram : F3','Mel Spectrogram : M1',
'Mel Spectrogram : M2','Mel Spectrogram : M2_low']
for i in range(7):
S = librosa.feature.melspectrogram(y_list[i], sr=sr_list[i], n_fft=512, hop_length=128)
S_DB = librosa.amplitude_to_db(S, ref=np.max)






Zero Crossing Rate
- 음파가 양에서 음으로 또는 음에서 양으로 바뀌는 비율
- 0(Zero)을 많이 지날수록 노이즈가 많다고 볼 수 있다.
for i in range(7) :
zero_crossings = librosa.zero_crossings(y_list[i], pad=False)
print('name : ', name[i],'\n')
print('zero_crossings : ', zero_crossings,'\n')
print('Total zero_crossings in our 1 file : ', sum(zero_crossings),'\n')
print('-------------------------------------------------------')
name : F1_high
zero_crossings : [False False True ... False False False]
Total zero_crossings in our 1 file : 12622
-------------------------------------------------------
name : F1
zero_crossings : [False False False ... False False False]
Total zero_crossings in our 1 file : 8582
-------------------------------------------------------
name : F2
zero_crossings : [False False False ... False True False]
Total zero_crossings in our 1 file : 6492
-------------------------------------------------------
name : F3
zero_crossings : [False False False ... True False False]
Total zero_crossings in our 1 file : 8226
-------------------------------------------------------
name : M1
zero_crossings : [False False False ... False False False]
Total zero_crossings in our 1 file : 6429
-------------------------------------------------------
name : M2
zero_crossings : [False False False ... False False False]
Total zero_crossings in our 1 file : 9286
-------------------------------------------------------
name : M2_low
zero_crossings : [False False False ... False False False]
Total zero_crossings in our 1 file : 9671
-------------------------------------------------------
Mel-Frequency Cepstral Coefficients (MFCCs)
- MFCCs는 특징들의 작은 집합(약 10-20)으로 스펙트럴 포곡선의 전체적인 모양을 축약하여 보여준다
- 사람의 청각 구조를 반영하여 음성 정보 추출
- mel spectrum에서 Cepstral분석을 통해 추출된 값
- 출처 : https://tech.kakaoenterprise.com/66
Cepstral?
Cepstrum(캡스트럼) = 스펙트럼 신호의 로그값에 역푸리에 변환을 한 것
(spectrum - cepstrum 단어를 거꾸로 하면 똑같은 단어가 된다!)
소리들은 기음(기본 주파수)와 배음으로 구성되어 있는데,
cepstral 분석을 하면 배음의 구조를 알 수 있어 기음을 찾을 수 있다.
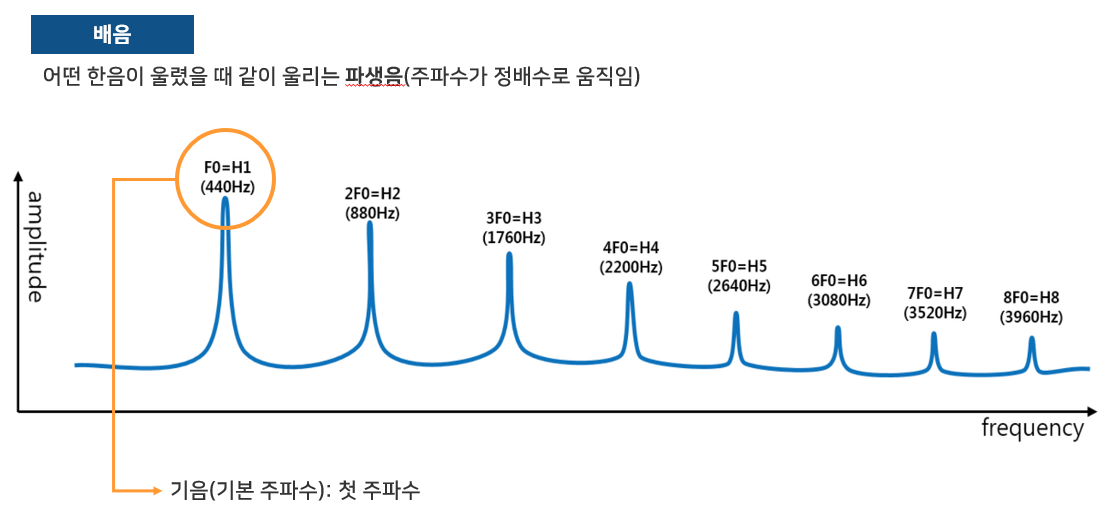
예를 들어 피아노에서 F0이 '라' 라고 한다면 '라'를 연주했을때 기본 주파수인 440hz뿐만 아니라
그 정수배인 880hz, 그리고 그 다음 배음들까지 포함하고 있다.
배음 구조는 악기나 성대의 구조에 따라 달라지며 배음 구조의 차이가 음색의 차이를 만든다.
librosa.feature.mfcc(y=None, sr=22050, S=None, n_mfcc=20,
dct_type=2, norm='ortho', lifter=0, **kwargs)import sklearn
title = ['MFCCs : F1_high','MFCCs : F1',
'MFCCs : F2','MFCCs : F3','MFCCs : M1',
'MFCCs : M2','MFCCs : M2_low']
for i in range(7):
mfccs = librosa.feature.mfcc(y_list[i], sr=sr_list[i])
print('mfccs shape:', mfccs.shape)
mfccs = sklearn.preprocessing.minmax_scale(mfccs, axis=1)
print('mean: %.2f' % mfccs.mean())
print('var: %.2f' % mfccs.var())
plt.figure(figsize=(16, 6))
librosa.display.specshow(mfccs, sr=sr_list[i], x_axis='time')
plt.title(title[i], fontsize=20)
plt.colorbar()
plt.show()
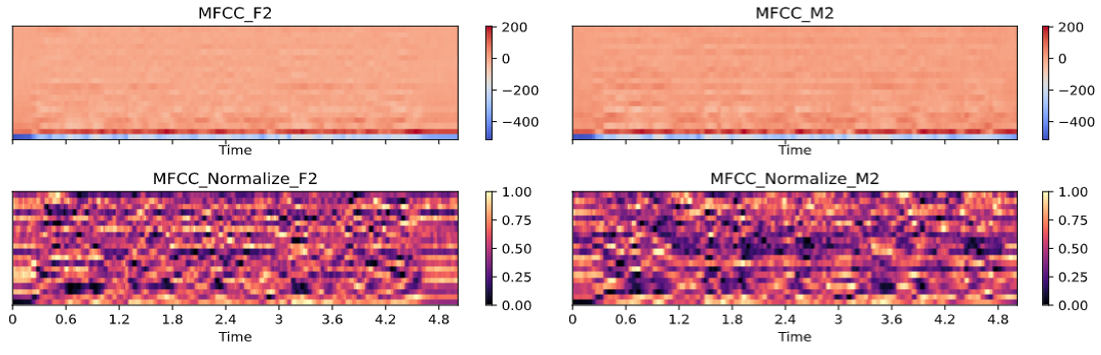
MFCC를 정규화 하지 않으면 상단의 그래프처럼 보인다. 너무 낮은 값이 있어서 제대로 특징을 볼 수 없다.







Chroma Frequencies
- 크로마 특징은 음악의 흥미롭고 강렬한 표현이다
- 크로마는 인간 청각이 옥타브 차이가 나는 주파수를 가진 두 음을 유사음으로 인지한다는 음악이론에 기반한다
- 모든 스펙트럼을 12개의 Bin으로 표현한다
- 12개의 Bin은 옥타브에서 12개의 각기 다른 반음(Semitones=Chroma)을 의미한다
title = ['Chroma Frequencies : F1_high','Chroma Frequencies : F1',
'Chroma Frequencies : F2','Chroma Frequencies : F3','Chroma Frequencies : M1',
'Chroma Frequencies : M2','Chroma Frequencies : M2_low']
for i in range(7):
chromagram = librosa.feature.chroma_stft(y_list[i], sr=sr_list[i], hop_length=512)
plt.figure(figsize=(16, 6))
librosa.display.specshow(chromagram, x_axis='time', y_axis='chroma', hop_length=512)
plt.title(title[i], fontsize=20)
plt.show()
print('Chromogram shape:', chromagram.shape)모든 Chromogram shape: (12, 216)으로 동일하다.







'민공지능 > 음성 인식 프로젝트' 카테고리의 다른 글
| STT (0) | 2021.04.26 |
|---|---|
| Speech VGG (0) | 2021.04.25 |
| librosa.feature (0) | 2021.04.03 |
| 음성 데이터 (오디오 파일 이해, 2D Sound Waves, Fourier Transform, Spectrogram) (0) | 2021.04.03 |