2021. 5. 23. 18:18ㆍ민공지능/딥러닝 & 머신러닝
네트워크를 구성할 때 사람이 조정해야 하는 파라미터가 존재한다. 이를 하이퍼파라미터라고 한다.
하이퍼파라미터 :
- 은닉층 수, 은닉층의 채널 수 → 예 : model.add(Dense(128))
- drop out 비율
- 활성화 함수(activation)
- 학습률(learning rate)
- batch_size
- epoch 수
- 오차 함수(loss)
- 최적화 함수(optimizer)
장점 / 단점
Optimizer(최적화 함수)
Gradient descent로 W를 업데이트 하는 알고리즘

GD(Gradient descent)

최적의 값을 찾기 위해 한 칸 전진할 때마다 전체를 고려해서 한 번씩 가중치를 수정하는 것은 시간이 너무 오래 걸린다.
SGD(Stochastic Gradient Desecent)

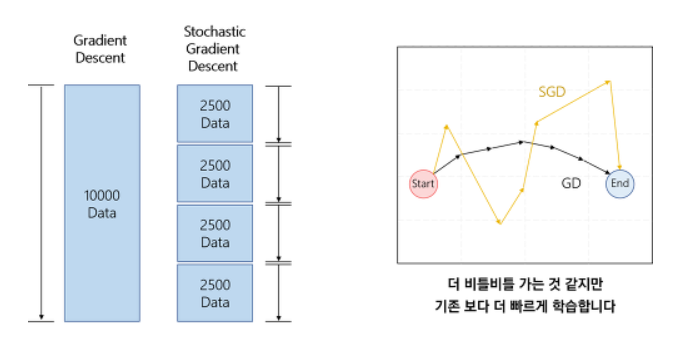
일부 데이터만 계산해서 GD보다는 빠르게 전진하지만 불안정한 학습과정으로 local minimum(지역 최소점)과 plateau(평지)에 빠져 더 이상 학습 진행이 안될 가능성이 높아진다.
+ 기존에는 지역최소점(local miniama = local optima)에 빠지는 문제를 해결하기 위해 optimization을 한다고 했지만, 요즘 trend에 의하면 실제 딥러닝에서는 w가 수도 없이 많으며, 그 많은 w가 모두 지역최소점에 빠져야 w업데이트가 정지되기 때문에 불가능한 일이라고 본다. 그래서 지역최소점은 고려할 필요가 없다는 것이 추세다.

그렇다면 요즘에 Optimization을 쓰는 이유는 무엇일까?

위의 그림에서 plateau(평지)가 생겨 loss가 업데이트 되지 않는 현상이 지역최소점에 비해 발생 확률이 높기 때문에 이 현상을 극복하기 위해 Gradient를 Optimization할 것이다.
Momentum
SGD의 문제(뭉뚝한 부분에서 느림, local minimum, plateau, 지그재그현상)를 해결하기 위해 Momentum 개념을 도입한다.

Momentum은 이전의 기울기 값에 이전 가속도를 추가하여 현재 가중치 값을 업데이트 한다.
이를 통해, 뭉뚝한 부분에서의 느림, local minimum, plateau 문제를 해결해준다.
단점은 Global optima에서도 이전 가속도가 더해지기 때문에 추월하는 현상이 발생한다.
(SGD에서 매개변수로 momentum의 값을 줄 때는 보통 0.9를 사용한다.)
NAG (Nesterov Accelerated Gradient)
Momentum을 먼저 진행한 상태에서 Gradient를 계산하여 더하면 추월하는 현상이 줄어든다.

성능이 크게 향상되지 않기 때문에 default optimizer로 momentum을 쓰면 된다.
AdaGrad

epsilon = 분모를 0으로 나누는 것을 방지하기 위한 설정

만약 x1, x2라는 데이터를 학습 시킬 때(입력 데이터들끼리의 범위 차이가 심하다는 가정)의 최소의 loss값을 구하려고 한다. 여기서 weight update 할 때는 동일한 learning rate(상수값)가 w1, w2에 적용하도록 한다. 그런데, loss 함수를 형성 했을 때 동일한 learning rate가 w1 loss 함수 기준에서는 적절할지 몰라도 w2 기준에서는 굉장히 큰 값이 될 수 있어서 위의 그림과 같이 지그재그로 학습하게 된다.
SGD의 이러한 지그재그 현상 문제에서 Adagrad는 각각의 가중치(ex : w1, w2)가 업데이트되는 정도에 따라서 step size를 조절하기 때문에 지그재그 현상을 피할 수 있다. 즉, 기울기가 가파를수록 조금만 이동하고, 완만할수록 조금 더 이동하면서 변동을 줄인다. 하지만, 가중치 업데이트 정도가 매우 커서 G의 값이 커질 때, step size(learning rate)가 매우 작아져 학습이 불가능해지는 상황이 발생된다.
+ 같은 입력 데이터가 여러번 학습되는 모델에 유용하게 쓰이며 언어와 관련된 word2vec이나 GloVe에 유용하다. (많이 등장한 단어는 가중치를 적게 수정하고 적게 등장한 단어는 많이 수정할 수 있기 때문)
RMSProp

감마를 통해 G에 대한 비중을 조절해준다. 기울기 제곱에 대한 지수평균을 구하는 것이라고 할 수 있다.(지수평균 : 보통 최근에 일어난 사례에 더 가중치를 준다는 개념. 무작정 step size를 줄이지 않는 역할) 즉, G에 대한 비중을 조절해 주면서 learning rate 소실 문제를 해결한다.
+ 짧은 이야기로 다음 단어를 예측하고 싶을 때 LSTM으로 사용하는 경우, 일반적으로 Adam과 SGD보다 RMSProp의 성능이 더 우수하다는 의견도 있다.
Adadelta

Adagrad, RMSprop, Momentum 모두를 합친 경사하강법이다. Adagrad 특징인 모든 step의 gradient 제곱의 합을 window size를 두어 window size만큼의 합으로 변경하고, 이후 RMSprop과 똑같이 지수이동평균을 적용한다. learning rate 설정 부분을 지우고 이를 자동화한다는 것에 의의. 즉, 고정적인 learning rate가 아닌, 변화하는 갱신값 delta를 사용한다. 그렇기 때문에 학습이 많이 진행되어도 가중치의 변화가 크게 일어난다면 학습률도 그에 맞게 계산된다.
Adam

가장 많이 쓰이는 optimizer다.
momentum(방향 중심) + RMSProp(보폭 중심)
RMSprop의 특징인 gradient의 제곱을 지수평균한 값을 사용하며 Momentum의 특징으로 gradient를 제곱하지 않은 값을 사용하여 지수평균을 구하고 수식에 활용한다.
Nadam

Adam에 NAG를 더해주어서 momentum을 보완해주었다.
optimizer의 자세한 수식과 내용은 여기 논문을 참고하세요.
https://arxiv.org/pdf/1609.04747.pdf
정리
- GD : batch를 사용해서 전체 데이터를 모두 학습해서 너무 느리다.
- SGD : mini-batch를 이용하여 GD의 시간문제는 해결했지만 작은 gradient때문에 local minimum, saddle point(안장점), plataeu에서 못빠져나간다. 또, 지그재그 학습으로 불안정한 학습 모습을 보여준다.
- Momentum : 가속도를 이용하여 SGD의 ocal minimum, saddle point(안장점), plataeu문제를 해결했다. 하지만 가속도로 인해 Global optima에서도 추월하는 현상 발생
- NAG : Momentum을 먼저 진행한 상태에서 Gradient를 계산하여 추월하는 현상 줄여줌
- Adagrad : SGD의 지그재그 현상을 해결하기 위해 각각의 가중치에 업데이트 되는 정도에 따라서 step size조절했다. 하지만, 무한히 학습하면 leanring rate(step size)가 매우 작아져 소실된다.
- RMSProp : Adagrad의 learning rate소실 문제를 해결하기 위해 감마를 통해 G에 대한 비중을 조정해준다.
- Adadelta : Adagrad의 learning rate 소실 문제를 해결하기 위해 변화하는 갱신값 delta를 사용해 learning rate의 값을 자동화시켰다.
- Adam : momentum(방향 중심) + RMSProp(step size 중심)
- Nadam : NAG + Adam
참고한 블로그 : https://twinw.tistory.com/247
수식과 코드로 보는 경사하강법(SGD,Momentum,NAG,Adagrad,RMSprop,Adam,AdaDelta)
1. 개요 가중치를 조절하는 방법으로 다들 경사 하강법을 알고 계실 것이라 생각합니다. 경사 하강법은 정확하게 가중치를 찾아가지만 가중치를 변경할때마다 전체 데이터에 대해 미분해야 하
twinw.tistory.com
https://nittaku.tistory.com/271
11. Optimization - local optima / plateau / zigzag현상의 등장
지난시간까지는 weight 초기화하는 방법에 대해 배웠다. activation func에 따라 다른 weight초기화 방법을 썼었다. 그렇게 하면 Layer를 더 쌓더라도 activation value(output)의 평균과 표준편차가 일정하게 유
nittaku.tistory.com
https://89douner.tistory.com/46?category=868069
12. Optimizer (결국 딥러닝은 최적화문제를 푸는거에요)
안녕하세요~ 지금까지는 DNN의 일반화성능에 초점을 맞추고 설명했어요. Batch normalization하는 것도 overfitting을 막기 위해서이고, Cross validation, L1,L2 regularization 하는 이유도 모두 overfitting의..
89douner.tistory.com
[딥러닝]딥러닝 최적화 알고리즘 알고 쓰자. 딥러닝 옵티마이저(optimizer) 총정리
재야의 숨은 고수가 되고 싶은 초심자
hiddenbeginner.github.io
'민공지능 > 딥러닝 & 머신러닝' 카테고리의 다른 글
| Language(python, C/C++, Java) (0) | 2021.05.29 |
|---|---|
| 머신 러닝(Machine Learning)? (0) | 2021.05.29 |
| 하이퍼파라미터 튜닝이란?(2) (0) | 2021.05.23 |
| 하이퍼파라미터 튜닝이란?(1) (0) | 2021.05.23 |
| Optuna (0) | 2021.05.22 |