네트워크를 구성할 때 사람이 조정해야 하는 파라미터가 존재한다. 이를 하이퍼파라미터라고 한다.
하이퍼파라미터 :
- 은닉층 수, 은닉층의 채널 수 → 예 : model.add(Dense(128))
- drop out 비율
- 활성화 함수(activation)
- 학습률(learning rate)
- batch_size
- epoch 수
- 오차 함수(loss)
- 최적화 함수(optimizer)
learning rate(학습률)
각 층의 가중치를 한 번에 어느 정도 변경할지 결정하는 하이퍼파라미터다.
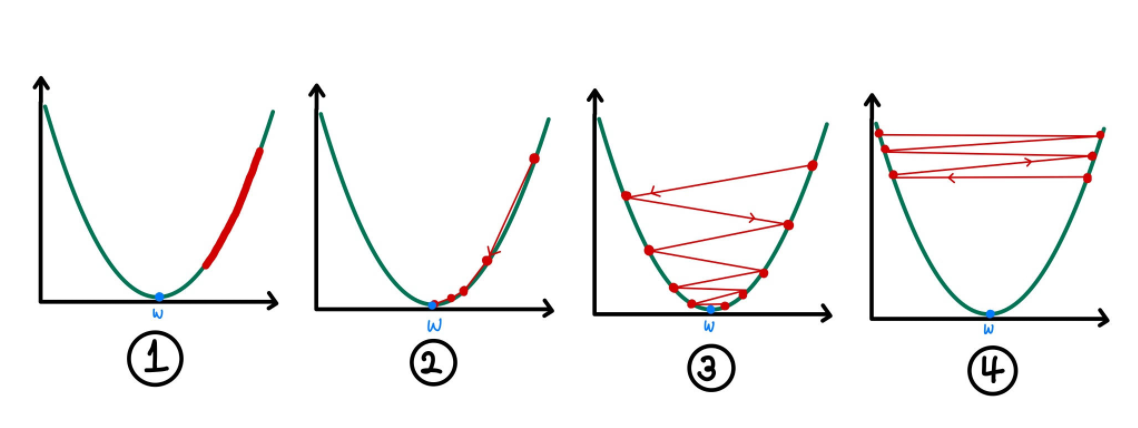
1번 : 학습률이 너무 낮아서 거의 갱신되지 않는다.
2번 : 적절한 학습률이므로 적은 횟수로 값이 수렴하고 있다.
3번 : 수렴하지만 값이 크므로 갱신 방법에 낭비가 있다.
4번 : 학습률이 너무 커서 퍼져버렸다.(상단에서 갱신되고 있다.)
learning rate를 다양하게 시도해보면서 적절한 learning rate를 구하는 것이 좋다.
batch size
- 모델의 학습을 실시할 때 한 번에 모델에 전달하는 입력 데이터 수를 바꿀 수 있다.
- 한 번에 전달하는 데이터 수를 배치크기(batch size)라고 한다.
- 한 번에 여러 데이터를 전달했을 때 모델은 각 데이터의 손실과 손실 함수의 기울기(가중치를 어떻게 갱신할 것인가)를 구하지만 가중치 갱신은 구해진 기울기의 평균으로 한 번만 실시된다.
- 편향된 데이터가 많을 때는 배치 크기를 크게 하고, 유사한 데이터가 많을 때는 배치 크기를 작게 하는 등 배치 크기를 잘 조정해야 한다.
- 배치 크기를 1로 하는 방식을 온라인 학습(확률적 경사하강법), 배치 크기를 전체 데이터 수로 지정하는 방식을 배치 학습(경사 하강법), 중간의 방식을 미니배치 학습이라고 한다.

배치 크기가 큰 상황에서는 오차를 최소화하는 방향이 이미 정해졌을 확률이 크기 때문에 오차가 최솟값이 아닌 극솟값에 빠져버린다. 이런 상황에서는 배치 크기가 작을수록 좋다. 특이값 데이터로 인해 실제와는 다른 방향의 기울기가 구해지면 가중치 값이 급격하게 변할 가능성이 커지기 때문이다.
epoch
모델의 정확도를 높이기 위해서 동일한 훈련 데이터를 사용하여 여러 번 학습시킨다.
이것을 반복 학습이라고 하며 학습할 횟수는 epoch수 이다.
epoch 수를 높인다고 해서 모델의 정확도가 계속 오르는 것은 아니다.
반복 학습으로 손실 함수를 최소화시키려 하면 과학습이 일어난다.
loss (오차 함수=손실 함수)
학습시 모델의 출려과 지도 데이터의 차이(잘못된 상태)를 평가하는 함수를 손실 함수라고 한다.
TensorFlow 공식 홈페이지에 나와있는 loss함수들이다.
내가 자주 쓰는 loss 함수들만 기록해두고 다른 loss 함수를 사용하는 경우가 생기면 추가로 기록하겠다.
MSE(mean squared error)
예측한 값과 실제 값 사이의 오차 제곱의 평균을 구한다.
차가 커질수록 제곱 연산으로 인해서 값이 더욱 뚜렷해진다.
단점으로는 값을 제곱하기 때문에 1미만의 값은 더 작아지고,
그 이상의 값은 더 커지는 것 처럼 값의 왜곡이 있을 수 있다.
회귀(regression)용도의 딥러닝 모델을 훈련시킬 때 많이 사용되는 손실 함수다.
MAE(mean absolute error)
예측한 값과 실제 값 사이의 오차 절댓값의 평균을 구한다.
전체 데이터의 학습된 정도를 쉽게 파악할 수 있지만, 절댓값을 취하기 때문에 해당 예측이 어떤 식으로 오차가 발생했는지, 음수인지 양수인지 판단할 수 없다는 단점이 있다.
회귀(regression)용도의 딥러닝 모델을 훈련시킬 때 많이 사용되는 손실 함수다.
tensorflow외에도 sklearn의 metrics를 사용해서 손실 함수를 볼 수 있다.
RMSE(Root Mean Square Error)
MSE에 루트를 씌운 지표다.
값을 제곱해서 생기는 왜곡이 줄어들며, 오차를 보다 직관적으로 보여준다.
RMSE는 낮을수록 좋다.
from sklearn.metrics import mean_squared_error
def RMSE(y_test, y_predict) :
return np.sqrt(mean_squared_error(y_test, y_predict))
print("RMSE : ", RMSE(y_test, y_predict))
binary crossentropy
이진 분류기로, True 또는 False처럼 2개의 클래스로 분류할 수 있다.
예측값이 0과 1사이의 확률값으로 나오기 때문에 1에 가까우면 하나의 클래스(예를 들어, True)일 확률이 큰 것이고, 0에 가까우면 다른 하나의 클래스(예를 들어,False)일 확률이 큰 것이다.
categorical crossentropy
멀티클래스 분류에 사용된다.
라벨이[[0 0 1] [0 1 0] [1 0 0]] 과 같이 one-hot 형태로 제공될 때 사용된다.
레이어 구성시 마지막에 activation='softmax'로 하여 클래스 별로 [0.2, 0.3, 0.5] 같은 식으로 나오기 때문에 여러 클래스 중 가장 적절한 하나의 클래스를 분류하는 문제에 사용하기 적합하다.
sparse categorical crossentropy
멀티클래스 분류에 사용된다.
라벨이 0,1,2,3,4 와 같이 정수의 형태로 제공될 때 사용된다.
별도의 원핫 인코딩을 하지 않고 정수값 그대로 줄 수 있다.
참고한 블로그 : https://bskyvision.com/822
딥러닝 손실 함수(loss function) 정리: MSE, MAE, binary/categorical/sparse categorical crossentropy
딥러닝 모델은 실제 라벨과 가장 가까운 값이 예측되도록 훈련되어집니다. 이때 그 가까운 정도를 측정하기 위해 사용되는 것이 손실 함수(loss funciton)입니다. 오늘은 많이 사용되는 손실 함수들
bskyvision.com
'민공지능 > 딥러닝 & 머신러닝' 카테고리의 다른 글
| 머신 러닝(Machine Learning)? (0) | 2021.05.29 |
|---|---|
| 하이퍼파라미터 튜닝이란?(3) (0) | 2021.05.23 |
| 하이퍼파라미터 튜닝이란?(1) (0) | 2021.05.23 |
| Optuna (0) | 2021.05.22 |
| SVM(Support Vector Machine) (0) | 2021.05.22 |



