2021. 5. 22. 21:32ㆍ민공지능/딥러닝 & 머신러닝
SVM은 선형이나 비선형 분류, 회귀, 이상치 탐색에도 사용할 수 있는 다목적 머신러닝 모델이다.
SVM은 특히 복잡한 분류 문제에 잘 들어맞으며 작거나 중간 크기의 데이터셋에 적합하다.
SVM의 장점 :
- 범주나 수치 예측 문제에 사용 가능하다.
- 오류 데이터에 대한 영향이 적다.
- 과적합 되는 경우가 적다.
- 신경망보다 사용하기 쉽다.
SVM의 단점 :
- 여러 개의 조합 테스트가 필요하다. 쵲거의 모델을 찾기 위해 커널과 모델에서 다양한 테스트를 해야한다.
- 학습 속도가 느리다
- 해석이 어렵고 복잡한 블랙박스 형태로 되어있다.
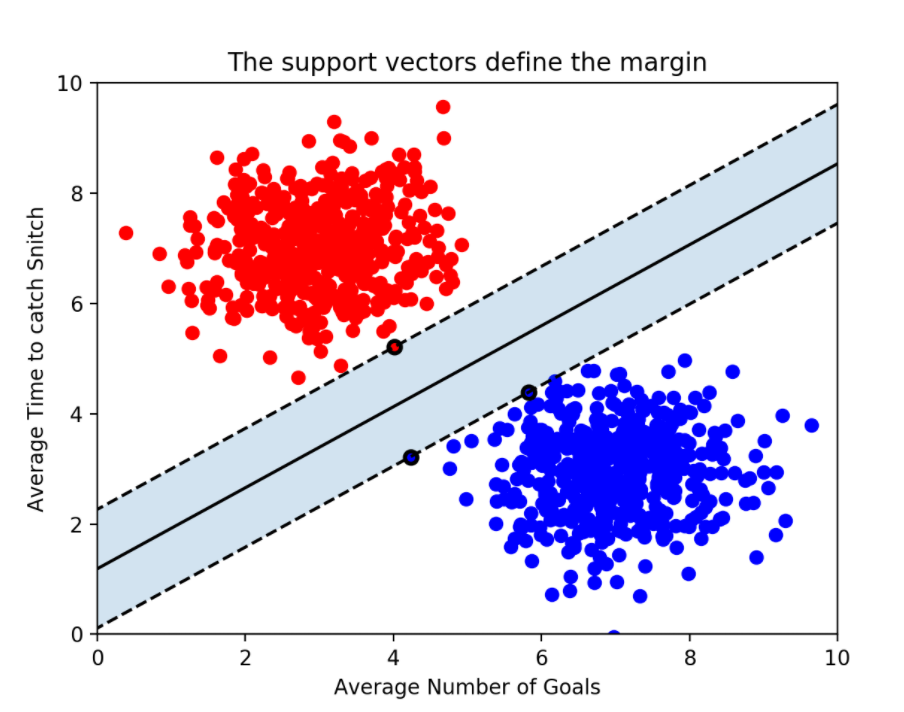
SVM 분류기를 클래스 사이에 가장 폭이 넓은 도로를 찾는 것으로 생각할 수 있다.
위의 그림에서 실선이 결정 경계이며 점선까지의 거리를 '마진(margin)'이라고 한다.
도로 경계에 위치한 샘플에 의해 전적으로 결정되는 샘플을 서포트 벡터(support vector)라고 한다.

SVM은 특성의 스케일에 민감하다. 왼쪽 그래프에서는 수직축의 스케일이 수평축의 스케일보다 훨씬 커서 가장 넓은 도로가 거의 수평에 가깝게 된다. 예를 들어 StandardScaler를 사용하여 스케일을 조정한다면 오른쪽 그래프처럼 결정 경계가 훨씬 좋아진다.
+ SVM 분류기는 로지스틱 회귀 분류기와는 다르게 클래스에 대한 확률을 제공하지 않는다.
+ SVM 모델이 과적합이면 C를 감소시켜 모델을 규제할 수 있다.
SVM 모델을 만들 때 여러 하이퍼 파라미터를 지정할 수 있다.
class sklearn.svm.SVC(C=1.0,
kernel='rbf',
degree=3,
gamma='scale',
coef0=0.0,
shrinking=True,
probability=False,
tol=0.001,
cache_size=200,
class_weight=None,
verbose=False,
max_iter=- 1,
decision_function_shape='ovr',
break_ties=False, random_state=None)C = SVM 모델이 오류를 어느정도 허용할 것인지 지정(기본 값은 1.0이다).C값이 클수록 하드마진(이상치에 민감하여 오류 허용 안함), 작을수록 소프트마진(오류를 허용함)이다.
kernel = 커널은 원래 가지고 있는 데이터를 더 높은 차원의 데이터로 변환한다. 'linear', 'poly', 'rbf', 'sigmoid', 'precomputed' 종류가 있으며 기본값은 'rbf'이다.
- linear : 선형
- poly : 다항식(polynomial) 커널을 사용하면 데이터를 더 높은 차원으로 변형하여 나타냄으로써 초평면(hyperplane)의 결정 경계를 얻을 수 있다. 3차원
- rbf : 방사 기저 함수(Radial Bias Function)는 2차원의 점을 무한한 차원의 점으로 변환한다. (유사도 특성 방식, 유사도 특성을 많이 추가하는 것과 같은 비슷한 결과를 얻을 수 있다.)
* 왜 더 높은 차원의 데이터로 변환할까? 현실에서는 선형으로 분리되지 않는 비선형 SVM이 많다. 이러한 비선형 SVM은 선형 SVM의 차원 확장을 통해 만들 수 있다. (예를 들어, 2차원에서는 선을 그어 분류할 수 없지만 3차원에서는 가능하다)
gamma : 결정 경계를 얼마나 유연하게 그을 것인지 지정. gamma값을 높이면 각 샘플을 따라 구불구불하게 휘어지면서 과대적합이 될 수 있으며, 값을 낮추면 넓은 범위에 영향을 주면서 결정 경계가 부드러워진다. 하지만 이는 과소적합이 될 수 있다. 결론, 모델이 과대적합일 경우엔 값을 감소시켜야 하며 과소적합일 경우엔 값을 증가시켜야 한다.
여러 가지 커널 중 어떤 것을 사용해야 할까? 선형 커널을 가장 먼저 시도해보는 것이 좋다.
(LinearSVC가 SVC(kernel = 'linear') 보다 훨씬 빠르다. 특히 train set이 아주 크거나 특성 수가 많을 경우에 그렇다.)
train set이 너무 크지 않다면 가우시안 rbf 커널도 시도해보면 좋다.
'민공지능 > 딥러닝 & 머신러닝' 카테고리의 다른 글
| 하이퍼파라미터 튜닝이란?(1) (0) | 2021.05.23 |
|---|---|
| Optuna (0) | 2021.05.22 |
| EfficientNet (0) | 2021.05.22 |
| TTA(Test Time Augmentation) (0) | 2021.05.22 |
| Scikit-Learn의 Scaler (0) | 2021.05.22 |